papers
Papers include publications and preprints in reverse chronological order; * denotes equal contribution.
2026
- arXiv
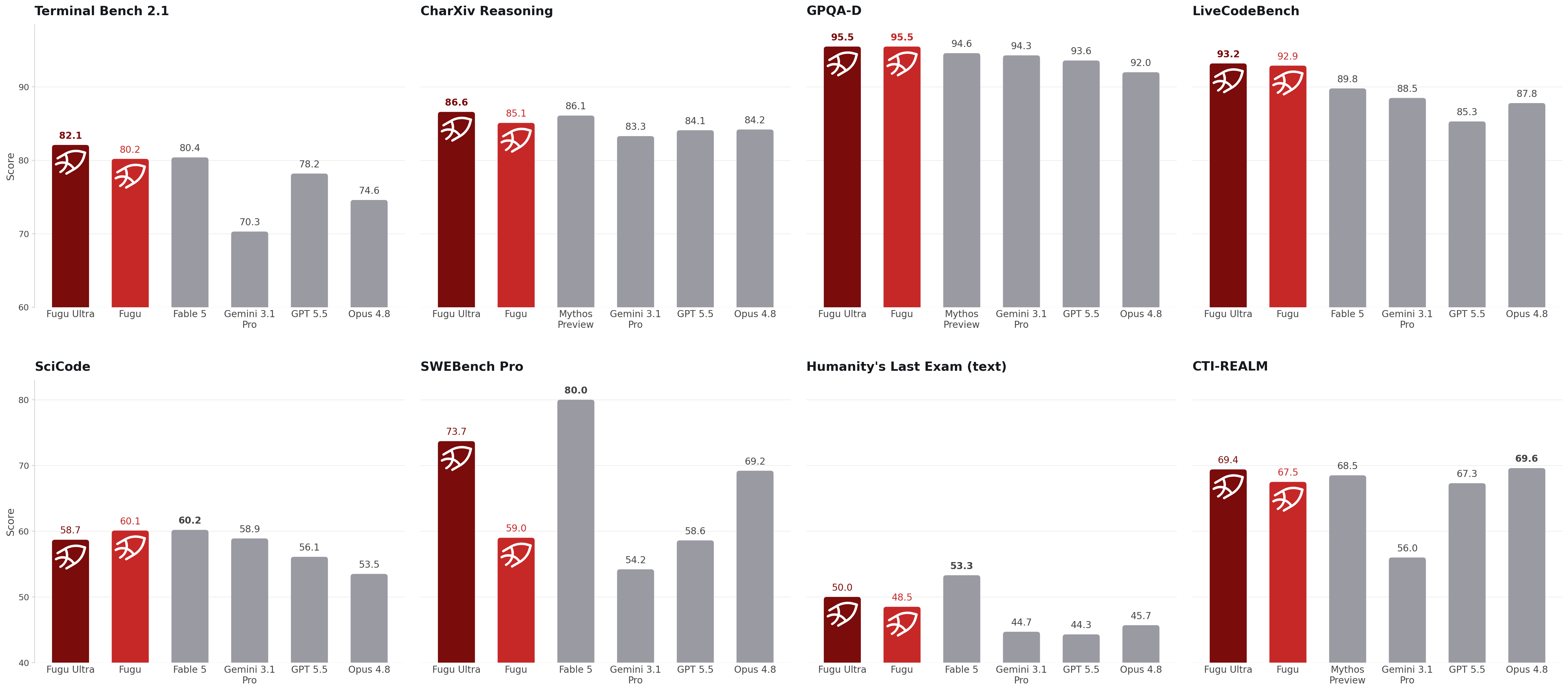 Sakana Fugu Technical ReportYujin Tang, Edoardo Cetin, Jinglue Xu, and 11 more authorsarXiv preprint arXiv:2606.21228, 2026
Sakana Fugu Technical ReportYujin Tang, Edoardo Cetin, Jinglue Xu, and 11 more authorsarXiv preprint arXiv:2606.21228, 2026The capabilities of frontier Large Language Models (LLMs) continue to advance, with different providers increasingly specializing in distinct domains. This raises a natural next objective: how to combine the individual specializations of various LLMs into a collectively intelligent system. To this end, we report the development of Sakana Fugu, a family of orchestrator models that harness and amplify the capabilities of an LLM agent team. Fugu models are themselves language models trained to understand user queries and dynamically devise agentic scaffolds to solve them. Through these adaptive scaffolds, Fugu accesses performance beyond any individual LLM agent, achieving state-of-the-art results compared to other publicly accessible models across a range of challenging tasks, including SWE-Bench Pro, Terminal Bench, LiveCodeBench, GPQA-Diamond, Humanity’s Last Exam, and CharXiv Reasoning. We release two models: Fugu, which balances performance with latency for everyday use, and Fugu-Ultra, which prioritizes answer quality on the hardest problems. We describe our training paradigm, which encompasses large-scale fine-tuning, evolutionary algorithms, and reinforcement learning approaches, along with the infrastructure and core design principles that turn these methods into a production system. We hope this report encourages further research into multi-agent systems and dynamic, query-adaptive agentic scaffolds as a path toward the next frontier of AI capabilities, accessed through collective intelligence.
- arXiv
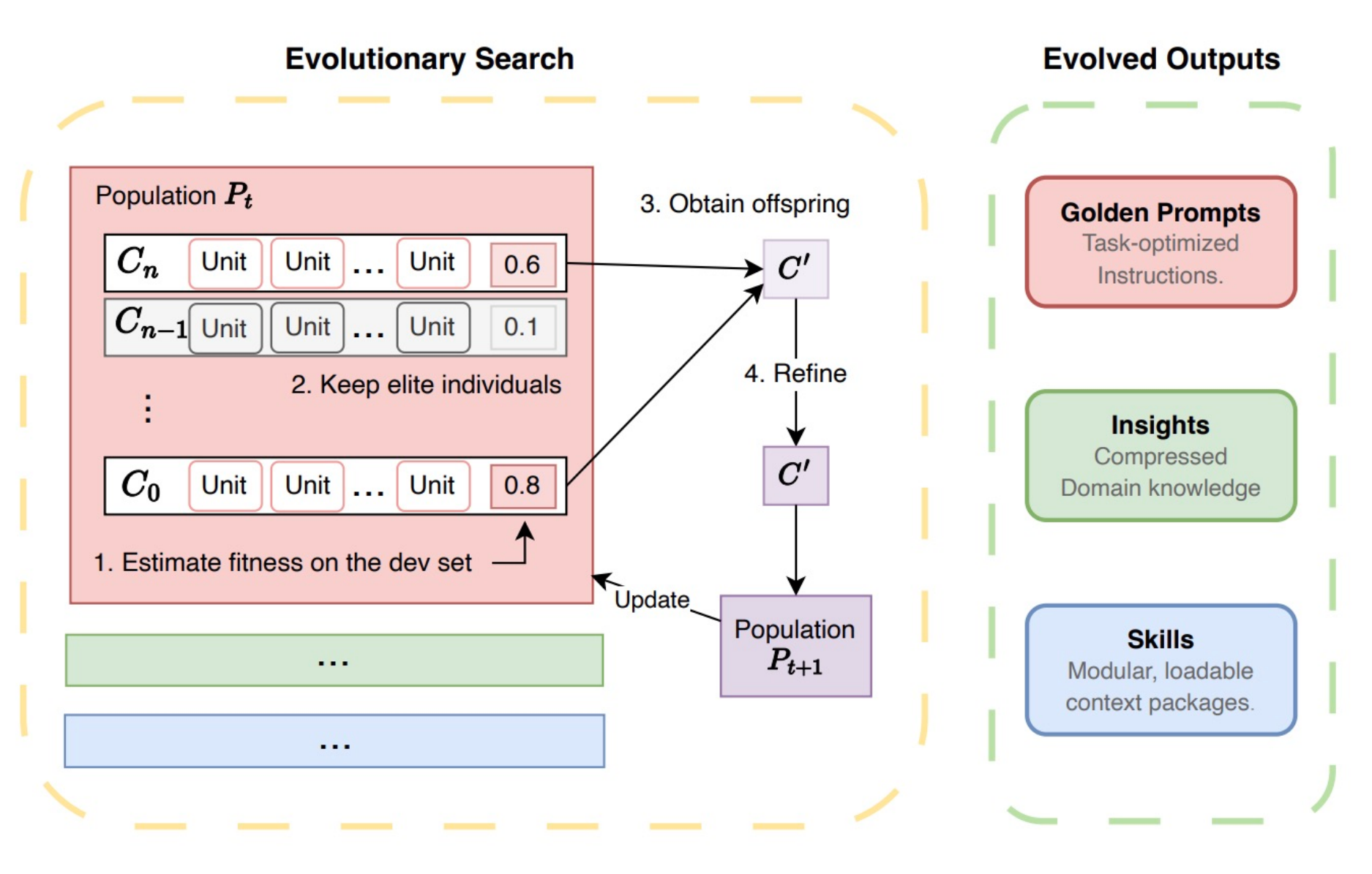 Evolutionary Context Search for Automated Skill AcquisitionQi Sun, Stefan Nielsen, Rio Yokota, and 1 more authorarXiv preprint arXiv:2602.16113, 2026
Evolutionary Context Search for Automated Skill AcquisitionQi Sun, Stefan Nielsen, Rio Yokota, and 1 more authorarXiv preprint arXiv:2602.16113, 2026Large Language Models cannot reliably acquire new knowledge post-deployment—even when relevant text resources exist, models fail to transform them into actionable knowledge without retraining. Retrieval-Augmented Generation attempts to bridge this gap by surfacing relevant documents at inference time, yet similarity-based retrieval often fails to identify context that actually improves task performance. We introduce Evolutionary Context Search (ECS), an evolutionary method that searches context combinations using accuracy on a small development set, requiring only inference calls without weight updates. ECS moves beyond semantic similarity to discover non-obvious context pairings that significantly boost performance. Our empirical results show that ECS improves BackendBench by 27% and τ-bench airline by 7%. The evolved contexts are model-agnostic, as those evolved with Gemini-3-Flash transfer effectively to Claude Sonnet and DeepSeek. This suggests that ECS opens a path toward automated context discovery for skill acquisition—an efficient alternative to manual prompt engineering or costly fine-tuning.
- ICLR
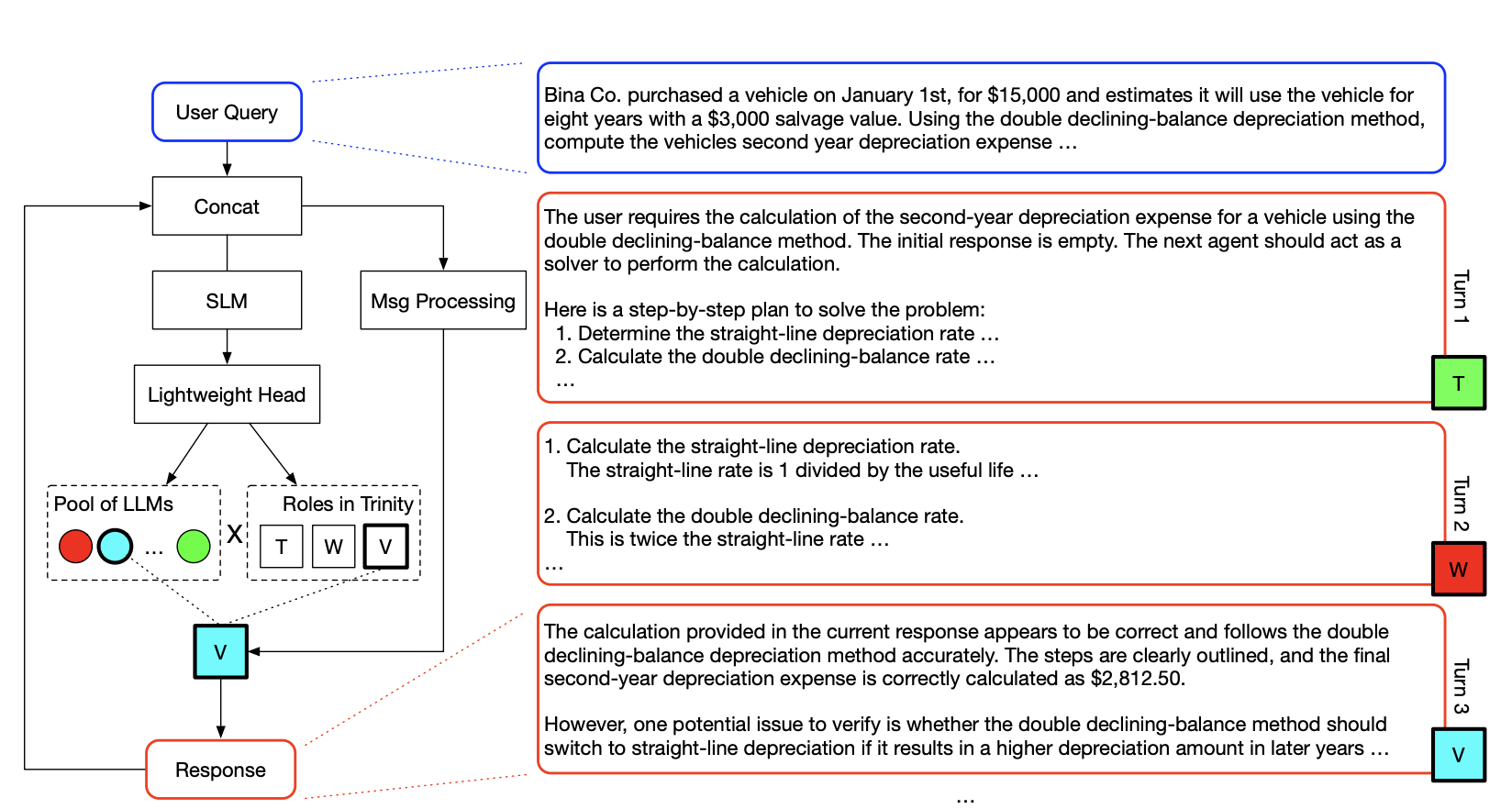 TRINITY: An Evolved LLM CoordinatorJinglue Xu*, Qi Sun*, Peter Schwendeman, and 3 more authorsIn International Conference on Learning Representations (ICLR), 2026
TRINITY: An Evolved LLM CoordinatorJinglue Xu*, Qi Sun*, Peter Schwendeman, and 3 more authorsIn International Conference on Learning Representations (ICLR), 2026Combining diverse foundation models is promising, but weight-merging is limited by mismatched architectures and closed APIs. Trinity addresses this with a lightweight coordinator that orchestrates collaboration among large language models (LLMs). The coordinator, comprising a compact language model (approximately 0.6B parameters) and a lightweight head (approximately 10K parameters), is optimized with an evolutionary strategy for efficient and adaptive delegation. Trinity processes queries over multiple turns, where at each turn the coordinator assigns one of three roles (Thinker, Worker, or Verifier) to a selected LLM, effectively offloading complex skill acquisition from the coordinator itself. Experiments show that Trinity consistently outperforms individual models and existing methods across coding, math, reasoning, and domain knowledge tasks, and generalizes robustly to out-of-distribution tasks. On standard benchmarks, Trinity achieves state-of-the-art results, including a score of 86.2% on LiveCodeBench. Theoretical and empirical analyses identify two main factors behind this performance: (1) the coordinator’s hidden-state representations provide rich contextualization of inputs, and (2) under high dimensionality and strict budget constraints, the separable Covariance Matrix Adaptation Evolution Strategy offers advantages over reinforcement learning, imitation learning, and random search by exploiting potential block-epsilon-separability.
- ICLR
 Learning to Orchestrate Agents in Natural Language with the ConductorStefan Nielsen*, Edoardo Cetin*, Peter Schwendeman*, and 3 more authorsIn International Conference on Learning Representations (ICLR), 2026
Learning to Orchestrate Agents in Natural Language with the ConductorStefan Nielsen*, Edoardo Cetin*, Peter Schwendeman*, and 3 more authorsIn International Conference on Learning Representations (ICLR), 2026Powerful large language models (LLMs) from different providers have been expensively trained and finetuned to specialize across varying domains. In this work, we introduce a new kind of Conductor model trained with reinforcement learning to automatically discover powerful coordination strategies among LLMs. Our Conductor learns not only to design targeted communication topologies for effective agent-to-agent collaboration, but also to prompt engineer focused instructions to the LLMs to maximally leverage their individual capabilities. We show that, by learning optimal coordination strategies over pools of powerful worker LLMs, a 7B Conductor achieves significant performance gains beyond any individual worker, attaining state-of-the-art results in challenging reasoning benchmarks, such as LiveCodeBench and GPQA. By training with randomized agent pools, our conductor effectively adapts to arbitrary sets of open- and closed-source agents, meeting any user requirements. Furthermore, allowing the Conductor to select itself as a worker gives rise to recursive topologies, elevating performance with a new form of dynamic test-time scaling through online iterative adaptation. More broadly, ours is among the early work demonstrating language model coordination can be unlocked through RL, where powerful coordination strategies emerge naturally in LLMs through pure end-to-end reward maximization.
2025
- Nature MI
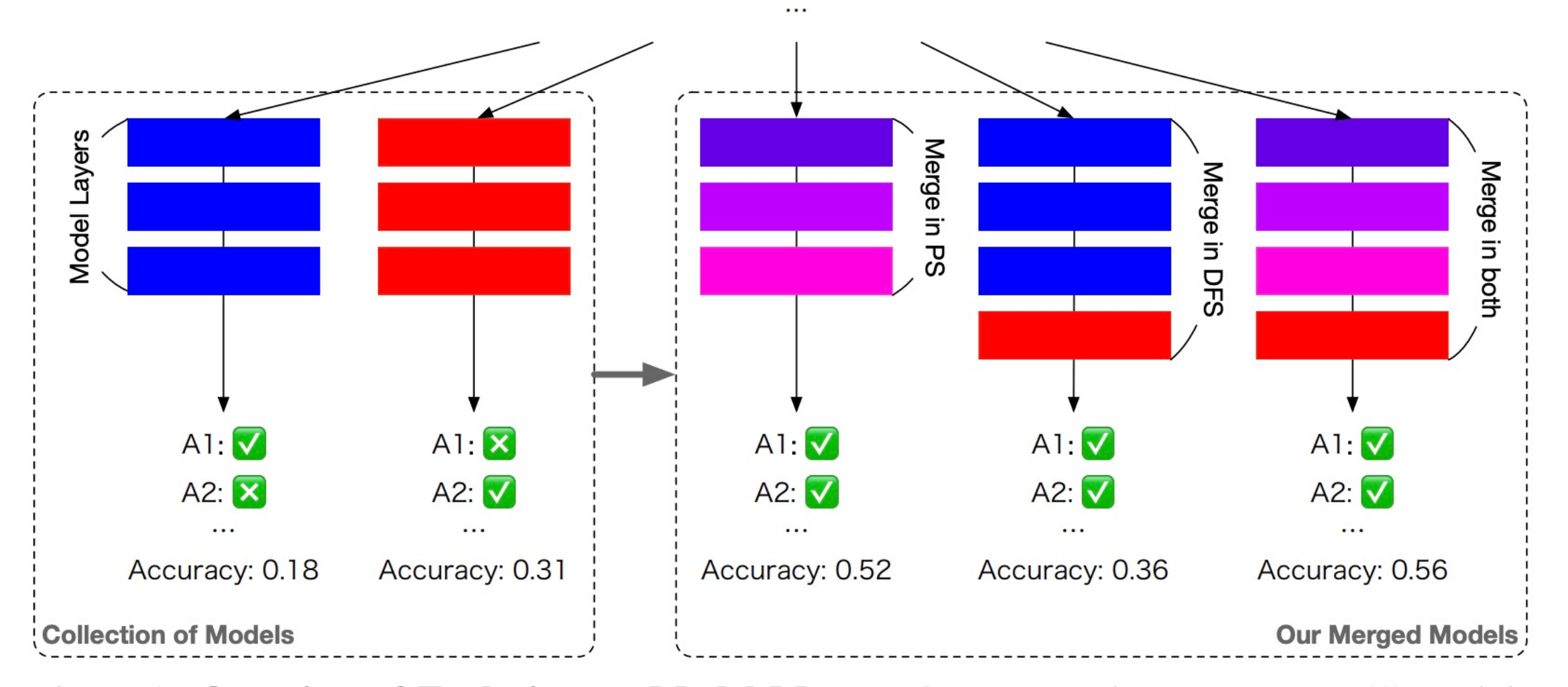 Evolutionary Optimization of Model Merging RecipesTakuya Akiba, Makoto Shing, Yujin Tang, and 2 more authorsNature Machine Intelligence, 2025
Evolutionary Optimization of Model Merging RecipesTakuya Akiba, Makoto Shing, Yujin Tang, and 2 more authorsNature Machine Intelligence, 2025Large language models (LLMs) have become increasingly capable, but their development often requires substantial computational resources. While model merging has emerged as a cost-effective promising approach for creating new models by combining existing ones, it currently relies on human intuition and domain knowledge, limiting its potential. Here, we propose an evolutionary approach that overcomes this limitation by automatically discovering effective combinations of diverse open-source models, harnessing their collective intelligence without requiring extensive additional training data or compute. Our approach operates in both parameter space and data flow space, allowing for optimization beyond just the weights of the individual models. This approach even facilitates cross-domain merging, generating models like a Japanese LLM with Math reasoning capabilities. Surprisingly, our Japanese Math LLM achieved state-of-the-art performance on a variety of established Japanese LLM benchmarks, even surpassing models with significantly more parameters, despite not being explicitly trained for such tasks. Furthermore, a culturally-aware Japanese VLM generated through our approach demonstrates its effectiveness in describing Japanese culture-specific content, outperforming previous Japanese VLMs. This work not only contributes new state-of-the-art models back to the open-source community, but also introduces a new paradigm for automated model composition, paving the way for exploring alternative, efficient approaches to foundation model development.
- ICLR
 Transformer-Squared: Self-adaptive LLMsQi Sun*, Edoardo Cetin*, and Yujin Tang*In International Conference on Learning Representations (ICLR), 2025
Transformer-Squared: Self-adaptive LLMsQi Sun*, Edoardo Cetin*, and Yujin Tang*In International Conference on Learning Representations (ICLR), 2025Self-adaptive large language models (LLMs) aim to solve the challenges posed by traditional fine-tuning methods, which are often computationally intensive and static in their ability to handle diverse tasks. We introduce Transformer-Squared, a novel self-adaptation framework that adapts LLMs for unseen tasks in real-time by selectively adjusting only the singular components of their weight matrices. During inference, Transformer-Squared employs a two-pass mechanism: first, a dispatch system identifies the task properties, and then task-specific "expert" vectors, trained using reinforcement learning, are dynamically mixed to obtain targeted behavior for the incoming prompt. Our method consistently outperforms ubiquitous approaches such as LoRA, with fewer parameters and greater efficiency. Furthermore, Transformer-Squared demonstrates versatility across different LLM architectures and modalities, including vision-language tasks. Transformer-Squared represents a significant leap forward, offering a scalable, efficient solution for enhancing the adaptability and task-specific performance of LLMs, paving the way for truly dynamic, self-organizing AI systems.
- AAAI
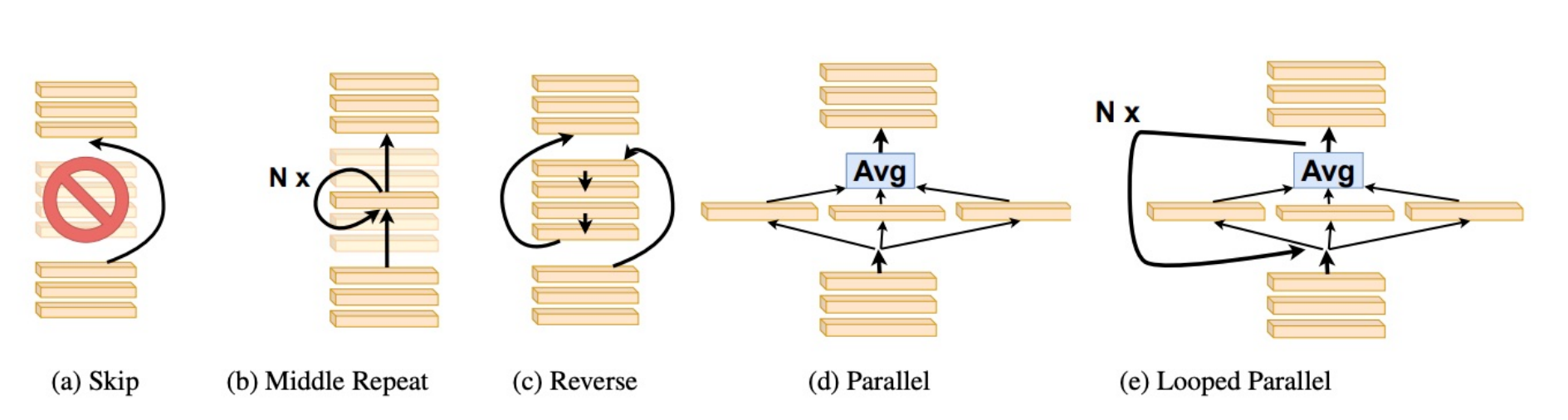 Transformer Layers as PaintersQi Sun*, Marc Pickett*, Aakash Kumar Nain, and 1 more authorIn Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025
Transformer Layers as PaintersQi Sun*, Marc Pickett*, Aakash Kumar Nain, and 1 more authorIn Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025Despite their nearly universal adoption for large language models, the internal workings of transformers are not well understood. We aim to better understand the impact of removing or reorganizing information throughout the layers of a pretrained transformer. Such an understanding could both yield better usage of existing models as well as to make architectural improvements to produce new variants. We present a series of empirical studies on frozen models that show that the lower and final layers of pretrained transformers differ from middle layers, but that middle layers have a surprising amount of uniformity. We further show that some classes of problems have robustness to skipping layers, running the layers in an order different from how they were trained, or running the layers in parallel. Our observations suggest that even frozen pretrained models may gracefully trade accuracy for latency by skipping layers or running layers in parallel.
- arXiv
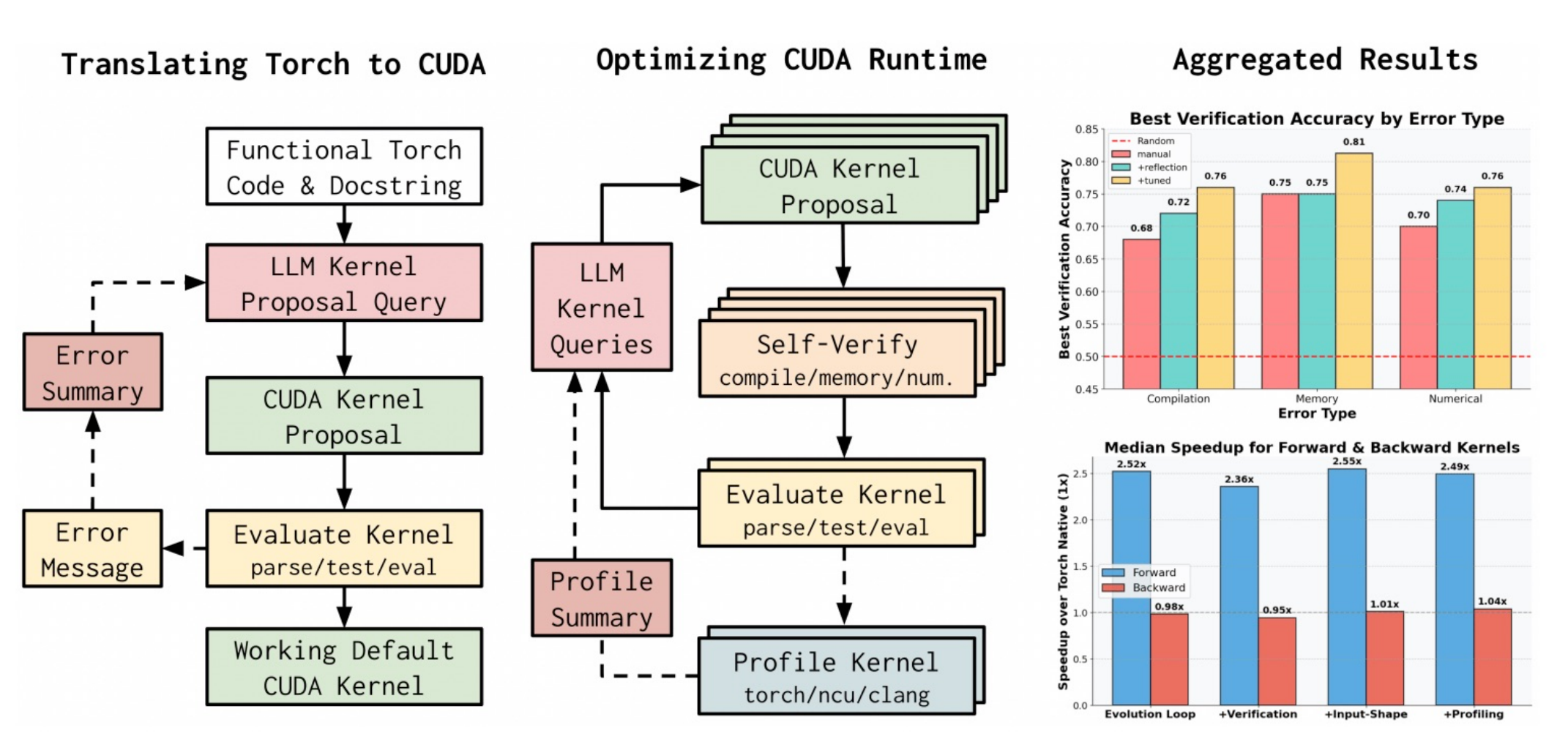 Towards Robust Agentic CUDA Kernel Benchmarking, Verification, and OptimizationRobert Tjarko Lange, Qi Sun, Aaditya Prasad, and 3 more authorsarXiv preprint arXiv:2509.14279, 2025
Towards Robust Agentic CUDA Kernel Benchmarking, Verification, and OptimizationRobert Tjarko Lange, Qi Sun, Aaditya Prasad, and 3 more authorsarXiv preprint arXiv:2509.14279, 2025Recent advances in large language models (LLMs) demonstrate their effectiveness in scaling test-time compute for software engineering tasks. However, these approaches often focus on high-level solutions, with limited attention to optimizing low-level CUDA kernel implementations. Additionally, existing kernel generation benchmarks suffer from exploitable loopholes and insufficient diversity in testing conditions, hindering true generalization assessment. To address these limitations, we introduce robust-kbench, a new benchmark for rigorous evaluation of kernel performance and correctness across varied scenarios. Furthermore, we present a comprehensive agentic framework that automates CUDA kernel discovery, verification, and optimization. This pipeline enables frontier LLMs to translate torch code to CUDA kernels and iteratively improve their runtime within our robust evaluation setting. Our sequential workflow first translates PyTorch code into equivalent CUDA kernels. It then optimizes their runtime using a novel evolutionary meta-generation procedure tailored to the CUDA ecosystem, guided by LLM-based verifiers for correctness and efficient filtering. Evaluated on robust-kbench, our approach produces CUDA kernels outperforming torch implementations for practical applications, including forward and backward passes. It can fuse operations and deploy various runtime optimization strategies. The verifier workflow accurately classifies incorrect kernels, enhancing hardware verification efficiency.
- ICLR
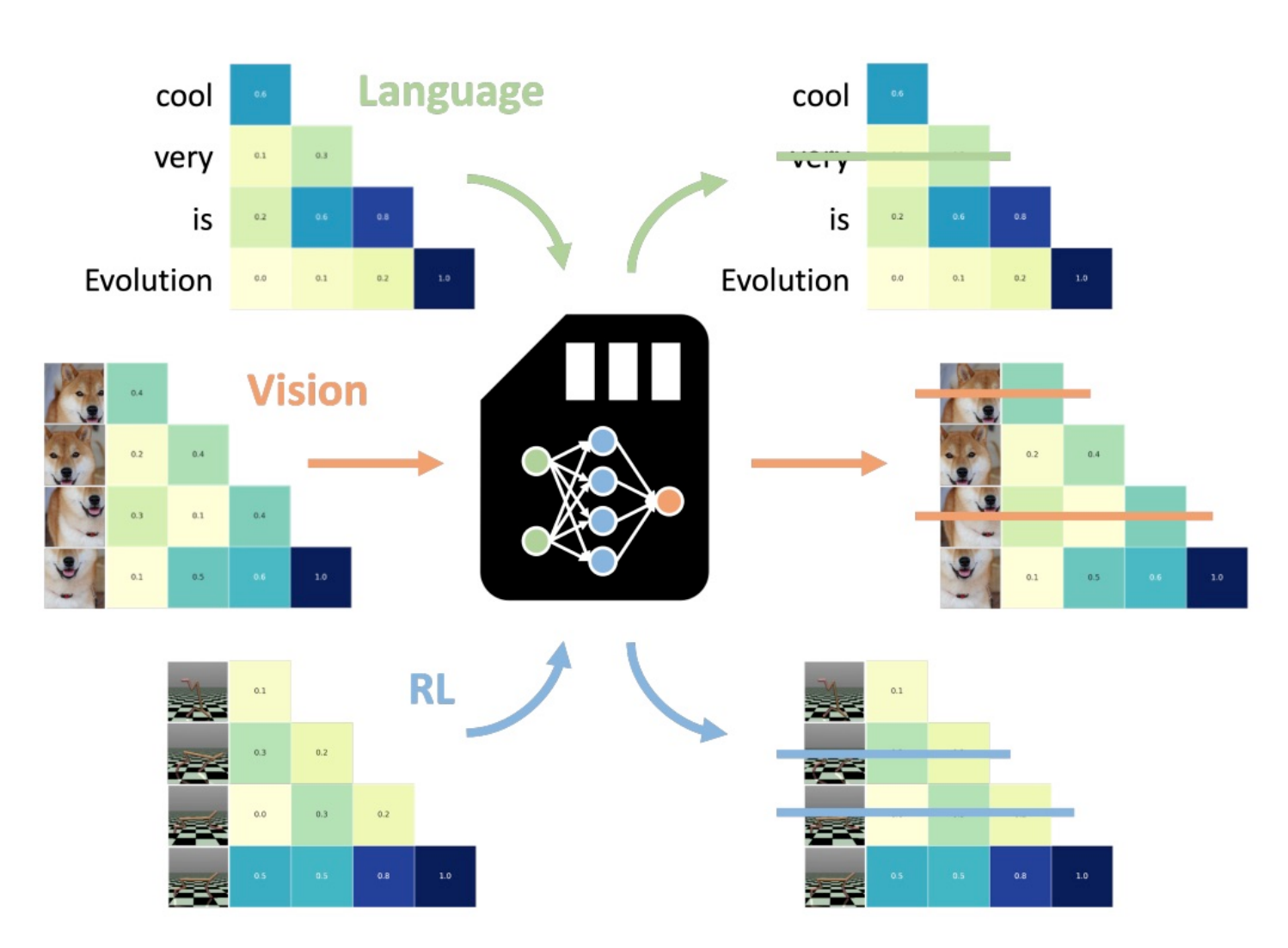 An Evolved Universal Transformer MemoryEdoardo Cetin, Qi Sun, Tianyu Zhao, and 1 more authorIn International Conference on Learning Representations (ICLR), 2025
An Evolved Universal Transformer MemoryEdoardo Cetin, Qi Sun, Tianyu Zhao, and 1 more authorIn International Conference on Learning Representations (ICLR), 2025Prior methods propose to offset the escalating costs of modern foundation models by dropping specific parts of their contexts with hand-designed rules, while attempting to preserve their original performance. We overcome this trade-off with Neural Attention Memory Models (NAMMs), introducing a learned network for memory management that improves both the performance and efficiency of transformers. We evolve NAMMs atop pre-trained transformers to provide different latent contexts focusing on the most relevant information for individual layers and attention heads. NAMMs are universally applicable to any model using self-attention as they condition exclusively on the values in the produced attention matrices. Learning NAMMs on a small set of problems, we achieve substantial performance improvements across multiple long-context benchmarks while cutting the model’s input contexts up to a fraction of the original sizes. We show the generality of our conditioning enables zero-shot transfer of NAMMs trained only on language to entirely new transformer architectures even across input modalities, with their benefits carrying over to vision and reinforcement learning.
- COLING
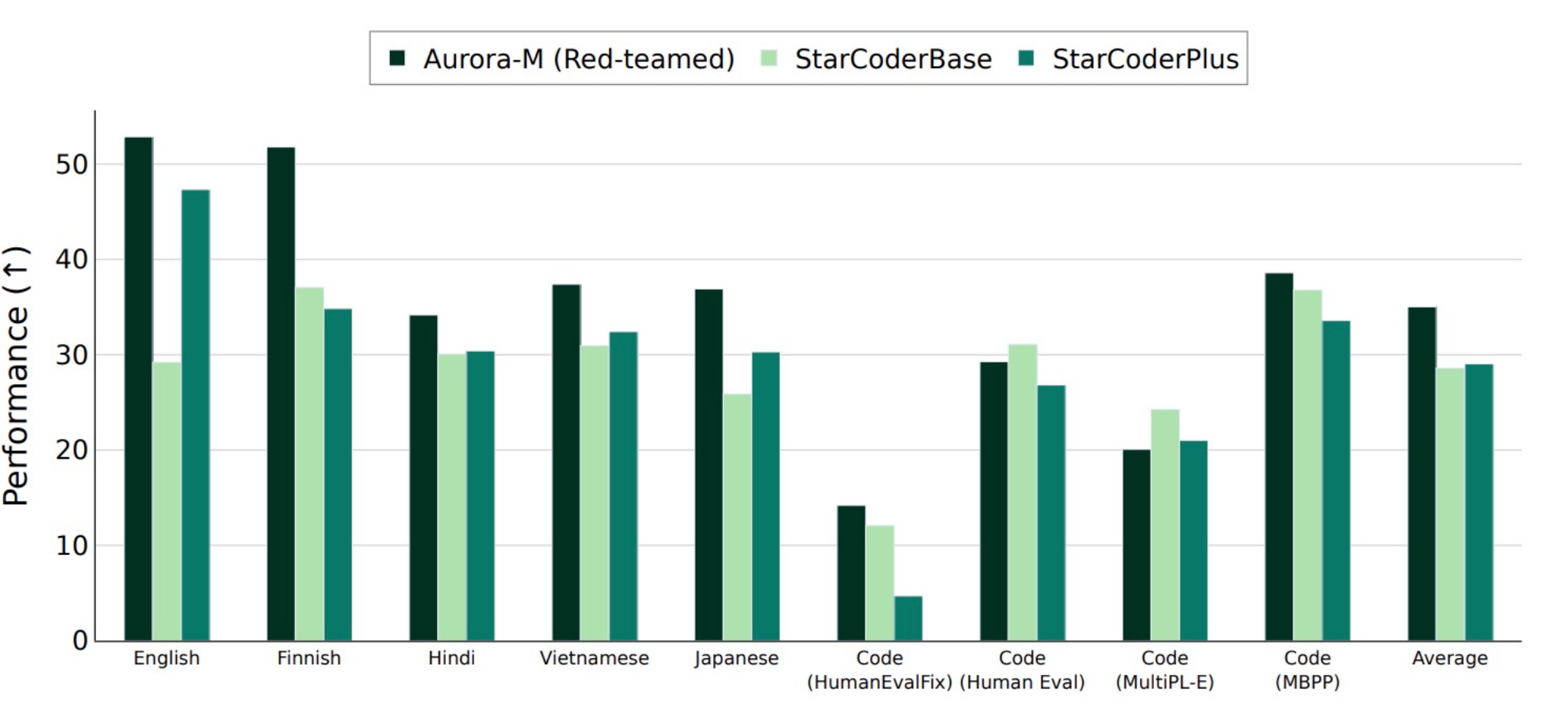 Aurora-M: Open Source Continual Pre-training for Multilingual Language and CodeTaishi Nakamura*, Mayank Mishra*, Simone Tedeschi*, and 38 more authorsIn Proceedings of the 31st International Conference on Computational Linguistics: Industry Track (COLING), 2025
Aurora-M: Open Source Continual Pre-training for Multilingual Language and CodeTaishi Nakamura*, Mayank Mishra*, Simone Tedeschi*, and 38 more authorsIn Proceedings of the 31st International Conference on Computational Linguistics: Industry Track (COLING), 2025Pretrained language models are integral part of AI applications, but their high computational cost for training limits accessibility. Initiatives such as Bloom and StarCoder aim to democratize access to pretrained models for collaborative community development. Despite these efforts, such models encounter challenges such as limited multilingual capabilities, risks of catastrophic forgetting during continual pretraining, and the high costs of training models from scratch, alongside the need to align with AI safety standards and regulatory frameworks. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435B additional tokens, Aurora-M surpasses 2T tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. We evaluate Aurora-M across a wide range of tasks and languages, showcasing its robustness against catastrophic forgetting and its superior performance in multilingual settings, particularly in safety evaluations. We open-source Aurora-M and its variants to encourage responsible open-source development of large language models at https://huggingface.co/aurora-m.